I have some anecdotes about some situations where humans introduce randomness in order to mutate the level of ethics of their pairs. I have been thinking about some examples situation, it might of course not be exhaustive, and if it makes you think of other similar situation, i would be really happy to hear them !
Randomized Responses
I cannot remember when i encountered this first idea but i think it was with in a youtube video from Le chat sceptique.
The situation takes place while taking a survey that contains sensitive questions. When you know the respondants will have social, legal or other pressure which could make them answer with bad faith.
I will focus on the most simple type of technique is the original idea from (Warner 1965) which propose a binary question to the surveyee.
We are interested in quantifying the proportion of people belonging to groups A and B. The first step is to make the surveyees take a random experiment only they can observe, the binary random experiment will return either A or B, and the surveyee only has to answer to yes or no depending on wether the random outcome was his/her true group.
We can do a little simulation :
n : number of surveyees (sample size)
p : parameter of the bernouilli random experiment
\(\pi\) : true proportion of people belonging to the sensitive group
Stats recap
Using the noise change the estimation and the probability of the answers of the surveyees is as follow :
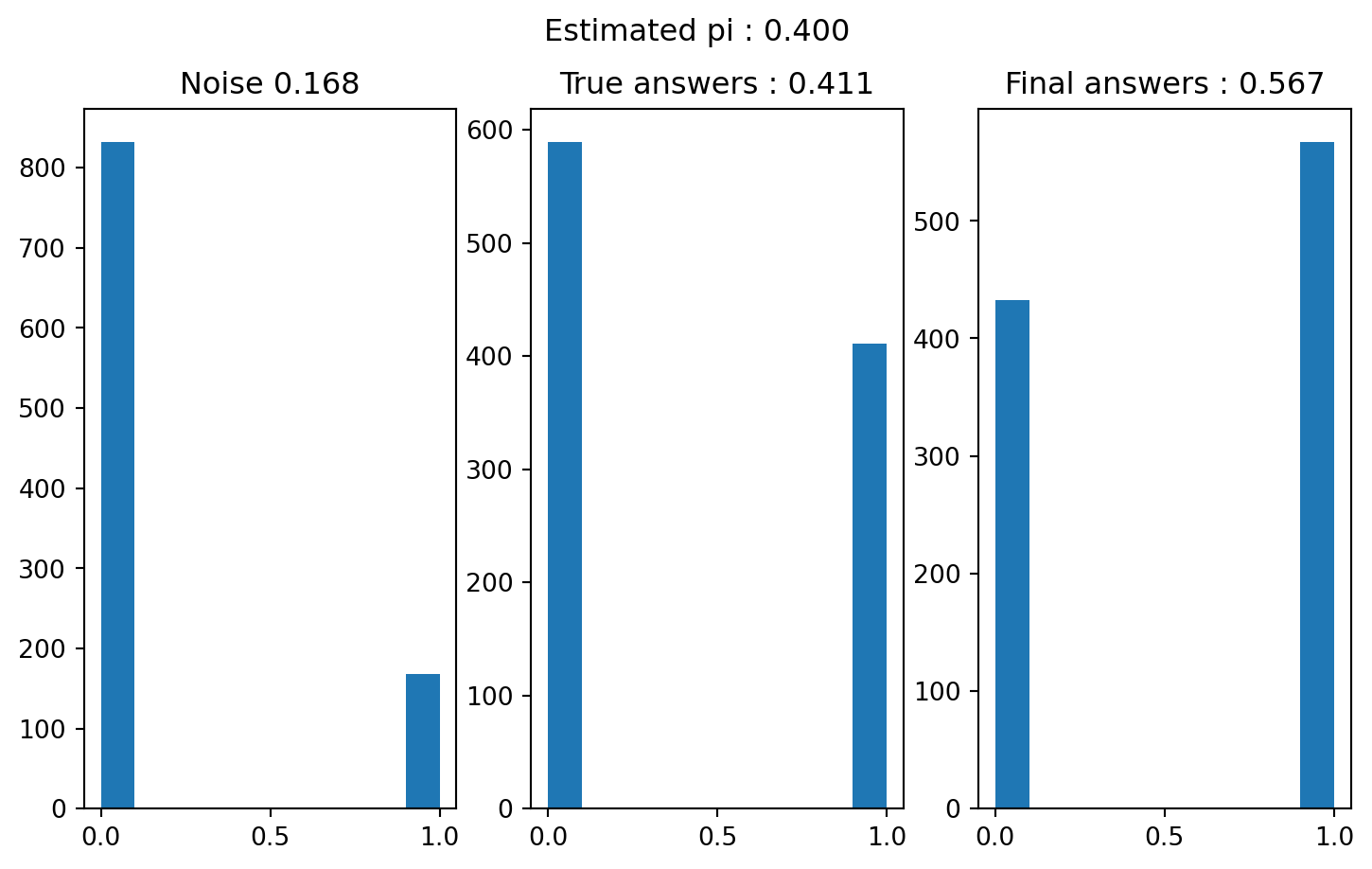
import numpy as npimport matplotlib.pyplot as pltimport plotly.express as pximport pandas as pdimport seaborn as snsn =1000p =1/6#(dice roll)pi =40/100true_answers = np.random.binomial(1, pi, n)noise = np.random.binomial(1, p, n) final_answer = (noise == true_answers).astype(int)n1 = final_answer.sum()pi_hat = (p-1)/(2*p -1) + (n1)/(n*(2*p -1))fig, axs = plt.subplots(nrows=1, ncols=3, figsize = (9, 5))axs[0].hist(noise)axs[0].set_title(f"Noise {noise.mean()}")axs[1].hist(true_answers)axs[1].set_title(f"True answers : {true_answers.mean()}")axs[2].hist(final_answer)axs[2].set_title(f"Final answers : {final_answer.mean()}")fig.suptitle(f"Estimated pi : {pi_hat:.3f}")
Text(0.5, 0.98, 'Estimated pi : 0.451')
Oh nice ! We could see on one sample how out maximum likelyhood estimator allows us to recover the true proportion. Let’s see how does the random event probability affect the ability to recover \(\pi\).
We will run multiple experiments with 100 surveyees.
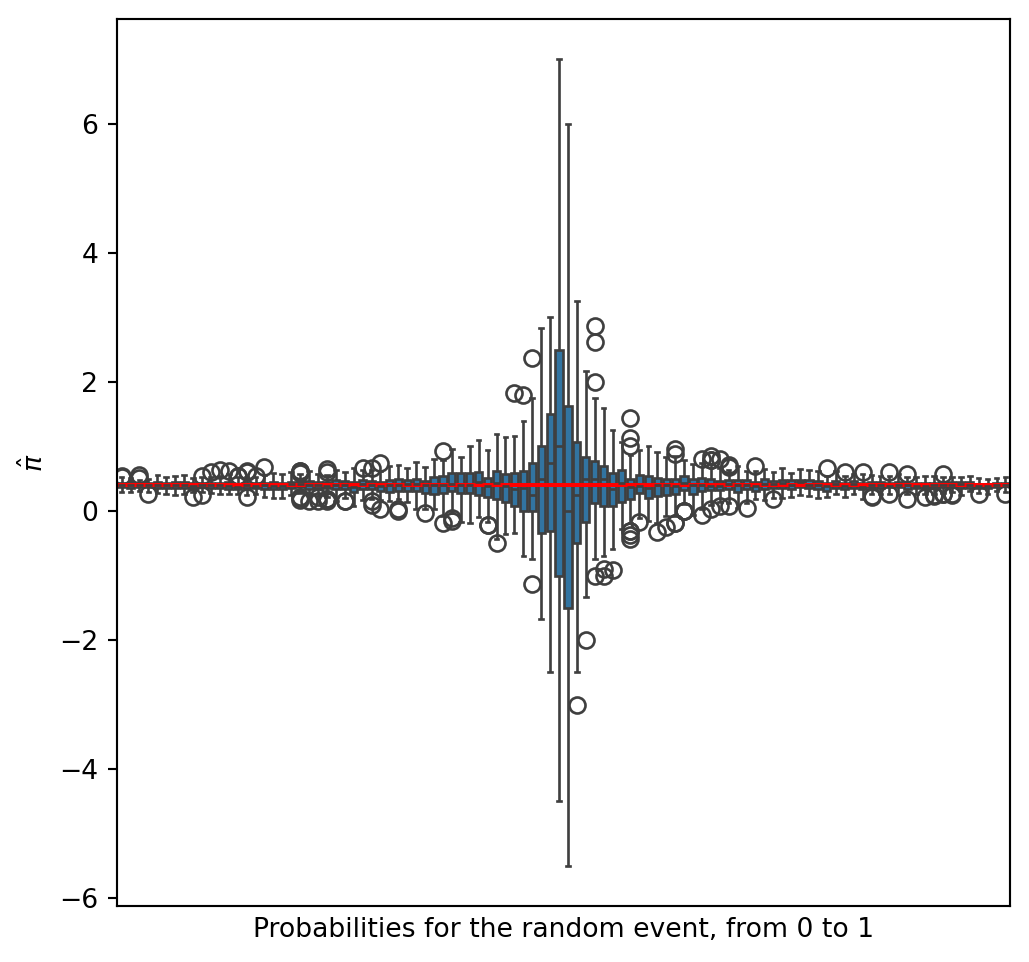
def get_pi_hat(p,n=100,pi=40/100)->float: true_answers = np.random.binomial(1, pi, n) noise = np.random.binomial(1, p, n) final_answer = (noise == true_answers).astype(int) n1 = final_answer.sum() pi_hat = (p-1)/(2*p -1) + (n1)/(n*(2*p -1))return pi_hatnum_ps =100mc_iter =100ps = np.zeros(num_ps * mc_iter)pihats = np.zeros(num_ps * mc_iter)pi =40/100i =0for p in np.linspace(0, 1, num_ps).round(2):for mc inrange(mc_iter): pihats[i] = get_pi_hat(p, pi = pi) ps[i] = p i+=1df= pd.DataFrame({"ps" : ps,"pihats" : pihats})plt.figure(figsize=(6,6))sns.boxplot(df, x="ps", y="pihats")plt.axhline(pi, c="red")plt.xlabel("Probabilities for the random event, from 0 to 1")plt.xticks([])plt.ylabel("$\\hat{\\pi}$")
Text(0, 0.5, '$\\hat{\\pi}$')
We can see that the estimator is centered around the true value of \(\pi\), but the closer we are to \(50\%\) the bigger the variance, indeed when the random event sucess probability the surveyee uses to answer is equal to \(50\%\), the answer provides no information at all.
So, the closer p is to 0 or 1, the better the estimation, but it will be more likely for the surveyee to answer with bad faith, the choice of p is a trade off between statistical efficiency and peoples’s trust.
Alternatives
Personal opinion
When running a survey, i would think their is a unspoken contract between surveyors and surveyees where surveyors ask questions for which answers help the greater good, and surveyees gives their precious time to make the population aware about global people behaviours, opinions etc… Taking a survey as a surveyee should not harm you or have a negative impact, that is why i personnaly like the approach taken in this article because the randomness affect both parties equally. It worsen the estimation for statisticians, but make people safe for answering on a good faith. Moreover, those questions of protecting surveyees while still gathering informatives answers are related to differential privacy (Karmitsa et al. 2026) which basically is a way of preventing adversarial actor to know wether a particular individual data has been used in a computation (Ioannidis, Litke, and Papadakis 2024). The list approaches where statisticians designs negatively correlated answers in the question pool in order to trace back more easily who answers what and reduce the noise to zero is a kind of disrespect to the trust surveyees gave us, but i am not working on surveys so i might be wrong. But the noise in the estimation is the trade off to pay for trust.
Conclusion
It was short and small, but it was very fun looking at this problem ! There are more recent extensions to overcome weaknesses of this methods, the field of randomized responses is very rich and i just wanted to share that this field even exists :) See you !
References
Ioannidis, Andreas, Antonios Litke, and Nikolaos Papadakis. 2024. “Randomized Response and Differential Privacy.” In Proceedings of the 17th International Conference on PErvasive Technologies Related to Assistive Environments, 600–605. PETRA ’24. New York, NY, USA: Association for Computing Machinery. https://doi.org/10.1145/3652037.3663902.
Karmitsa, Napsu, Antti Airola, Tapio Pahikkala, and Tinja Pitkämäki. 2026. “A Comprehensive Guide to Differential Privacy: From Theory to User Expectations.” arXiv. https://doi.org/10.48550/arXiv.2509.03294.
“(PDF) Randomized Response Techniques: A Systematic Review from the Pioneering Work of Warner (1965) to the Present.” 2025. ResearchGate, October. https://doi.org/10.3390/math11071718.
Warner, Stanley L. 1965. “Randomized Response: A Survey Technique for Eliminating Evasive Answer Bias.”Journal of the American Statistical Association 60 (309): 63–69. https://doi.org/10.2307/2283137.
Source Code
---title: "Randomness and ethics"author: "Julien Combes"date: "2026-01-10"categories: [Probabilities, ENG]image: "image.png"bibliography: ../../biblio.bib---I have some anecdotes about some situations where humans introduce randomness in order to mutate the level of ethics of their pairs.I have been thinking about some examples situation, it might of course not be exhaustive, and if it makes you think of other similar situation, i would be really happy to hear them !## Randomized ResponsesI cannot remember when i encountered this first idea but i think it was with in a youtube video from [Le chat sceptique](https://www.youtube.com/@ChatSceptique/videos).The situation takes place while taking a survey that contains sensitive questions. When you know the respondants will have social, legal or other pressure which could make them answer with bad faith.Randomized Responses are a category of techniques that use randomness to allow the respondent to answer with their true self, while having less or no pressure about answering. The paper i used to get introduced to this field is this review : [@PDFRandomizedResponse2025], but i am a strong beginner so do not take what i say for truth ! I will focus on the most simple type of technique is the original idea from [@warnerRandomizedResponseSurvey1965] which propose a binary question to the surveyee. We are interested in quantifying the proportion of people belonging to groups A and B. The first step is to make the surveyees take a random experiment only they can observe, the binary random experiment will return either A or B, and the surveyee only has to answer to yes or no depending on wether the random outcome was his/her true group. We can do a little simulation : - n : number of surveyees (sample size)- p : parameter of the bernouilli random experiment- $\pi$ : true proportion of people belonging to the sensitive group## Stats recapUsing the noise change the estimation and the probability of the answers of the surveyees is as follow : $$P(X_i = 1) = \pi p + (1 - \pi)(1 - p)$$$$P(X_i = 0) = (1 - \pi)p + + \pi(1 - p)$$Which leads to a estimation [see the the original paper from @warnerRandomizedResponseSurvey1965 details] :$$\hat{\pi} = \frac{p-1}{2p-1} + \frac{n_1}{n(2p - 1)}$$```{python}import numpy as npimport matplotlib.pyplot as pltimport plotly.express as pximport pandas as pdimport seaborn as snsn =1000p =1/6#(dice roll)pi =40/100true_answers = np.random.binomial(1, pi, n)noise = np.random.binomial(1, p, n) final_answer = (noise == true_answers).astype(int)n1 = final_answer.sum()pi_hat = (p-1)/(2*p -1) + (n1)/(n*(2*p -1))fig, axs = plt.subplots(nrows=1, ncols=3, figsize = (9, 5))axs[0].hist(noise)axs[0].set_title(f"Noise {noise.mean()}")axs[1].hist(true_answers)axs[1].set_title(f"True answers : {true_answers.mean()}")axs[2].hist(final_answer)axs[2].set_title(f"Final answers : {final_answer.mean()}")fig.suptitle(f"Estimated pi : {pi_hat:.3f}")```Oh nice ! We could see on one sample how out maximum likelyhood estimator allows us to recover the true proportion. Let's see how does the random event probability affect the ability to recover $\pi$.We will run multiple experiments with 100 surveyees.```{python}#| code-fold: falsedef get_pi_hat(p,n=100,pi=40/100)->float: true_answers = np.random.binomial(1, pi, n) noise = np.random.binomial(1, p, n) final_answer = (noise == true_answers).astype(int) n1 = final_answer.sum() pi_hat = (p-1)/(2*p -1) + (n1)/(n*(2*p -1))return pi_hatnum_ps =100mc_iter =100ps = np.zeros(num_ps * mc_iter)pihats = np.zeros(num_ps * mc_iter)pi =40/100i =0for p in np.linspace(0, 1, num_ps).round(2):for mc inrange(mc_iter): pihats[i] = get_pi_hat(p, pi = pi) ps[i] = p i+=1df= pd.DataFrame({"ps" : ps,"pihats" : pihats})plt.figure(figsize=(6,6))sns.boxplot(df, x="ps", y="pihats")plt.axhline(pi, c="red")plt.xlabel("Probabilities for the random event, from 0 to 1")plt.xticks([])plt.ylabel("$\\hat{\\pi}$")```We can see that the estimator is centered around the true value of $\pi$, but the closer we are to $50\%$ the bigger the variance, indeed when the random event sucess probability the surveyee uses to answer is equal to $50\%$, the answer provides no information at all. So, the closer p is to 0 or 1, the better the estimation, but it will be more likely for the surveyee to answer with bad faith, the choice of p is a trade off between statistical efficiency and peoples's trust.## Alternatives## Personal opinionWhen running a survey, i would think their is a unspoken contract between surveyors and surveyees where surveyors ask questions for which answers help the greater good, and surveyees gives their precious time to make the population aware about global people behaviours, opinions etc...Taking a survey as a surveyee should not harm you or have a negative impact, that is why i personnaly like the approach taken in this article because the randomness affect both parties equally. It worsen the estimation for statisticians, but make people safe for answering on a good faith.Moreover, those questions of protecting surveyees while still gathering informatives answers are related to differential privacy [@karmitsaComprehensiveGuideDifferential2026] which basically is a way of preventing adversarial actor to know wether a particular individual data has been used in a computation [@ioannidisRandomizedResponseDifferential2024]. The list approaches where statisticians designs negatively correlated answers in the question pool in order to trace back more easily who answers what and reduce the noise to zero is a kind of disrespect to the trust surveyees gave us, but i am not working on surveys so i might be wrong. But the noise in the estimation is the trade off to pay for trust.## Conclusion It was short and small, but it was very fun looking at this problem ! There are more recent extensions to overcome weaknesses of this methods, the field of randomized responses is very rich and i just wanted to share that this field even exists :) See you !